By: Divya Vijayaraghavan, Technical Leader, Altera
As the CXL ecosystem evolves, multiple use cases have emerged with two prominent frontrunners – active memory tiering and near memory compute acceleration.
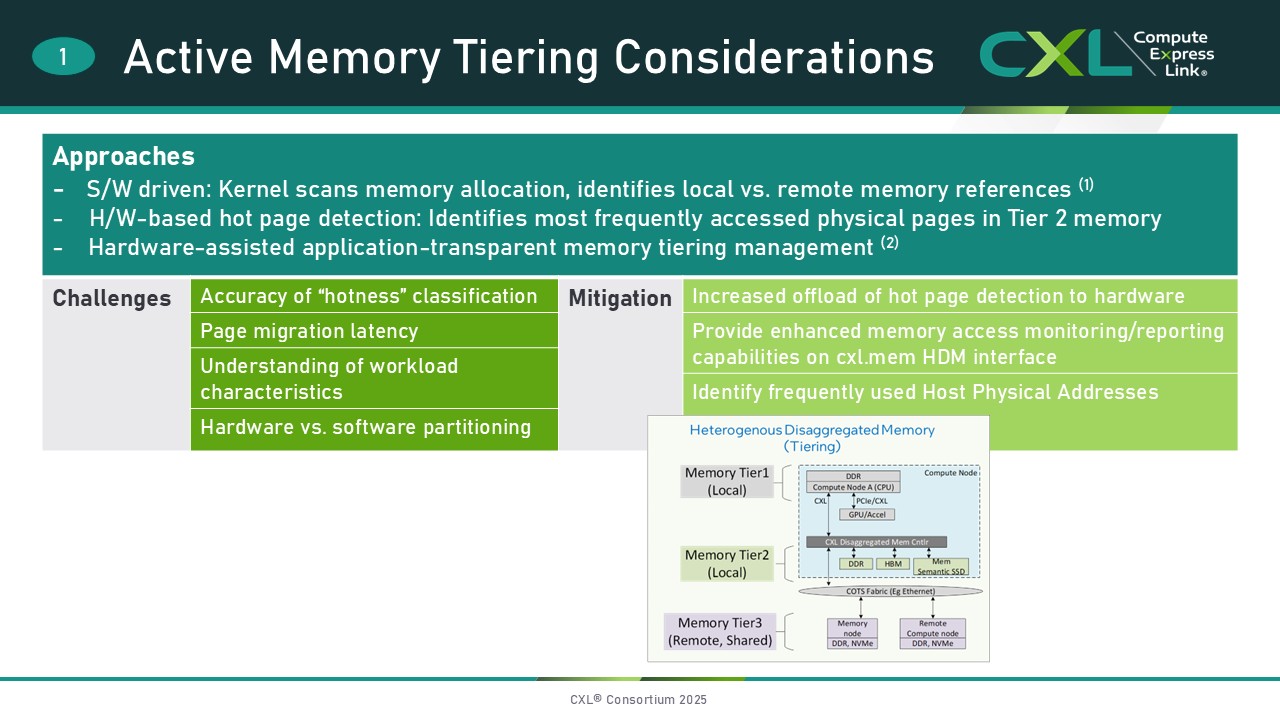
- Active memory tiering utilizes schemes to migrate hot and cold pages between local and remote memory tiers in a system. The term hot is synonymous with frequently accessed.
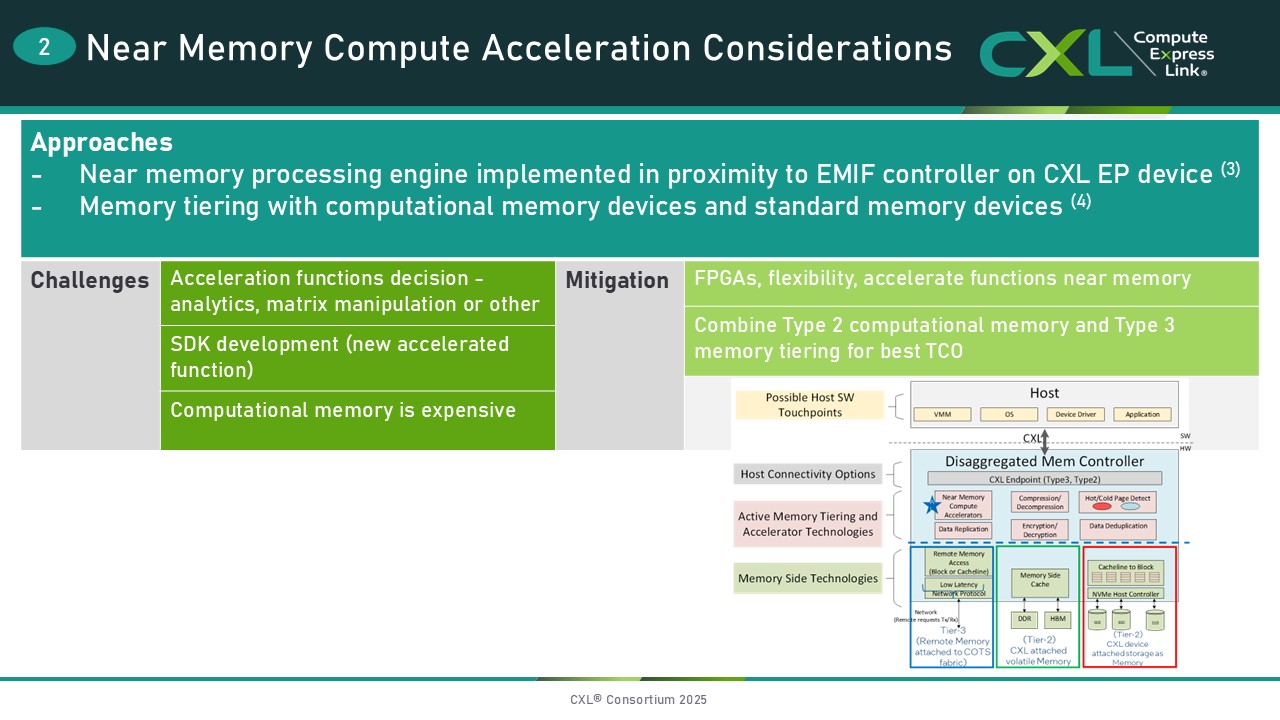
- Near memory compute acceleration, also called computational memory, is used to describe processing or acceleration performed near the remote memory in a system.
There are multiple approaches to implementing active memory tiering in the industry – software-driven, hardware-driven, and a combination of the two, but universal challenges remain. How accurate is the hot-page classification, how quickly can a system act on the classification and migrate pages, which workloads benefit from tiering, and which functions are implemented in hardware vs. software? In general, systems have been trending towards an increased offload of hot-page detection to hardware and enhanced memory access reporting capabilities are consequently provided on the cxl.mem HDM (Host Managed Device Memory) interface.
In the near memory compute acceleration use case, a function is typically offloaded from the CPU and processed or accelerated close to the EMIF (External Memory Interface) controller on the CXL device. Challenges include determining which workload or function to accelerate, the implementation of a Software Development Kit (SDK) for the accelerated function, and the prohibitive cost of computational memory. One way to mitigate these challenges is to utilize FPGAs to accelerate functions near the device-attached memory, providing the flexibility to experiment with workloads to determine which functions are most conducive to performance improvements. System TCO (Total Cost of Ownership) could be reduced by combining memory tiering and computational memory.
The figures below show a memory tiering solution implemented on Altera’s Agilex 7 FPGA. On the left, the host DRAM is able to service only about 50% of the CPU, with the rest of the CPU starved for memory! On the right, pages have been classified. Infrequently used pages are assigned to a cheaper memory tier, freeing up 40% of the host DRAM, which can be used to service the portion of the CPU that was previously starved for memory.

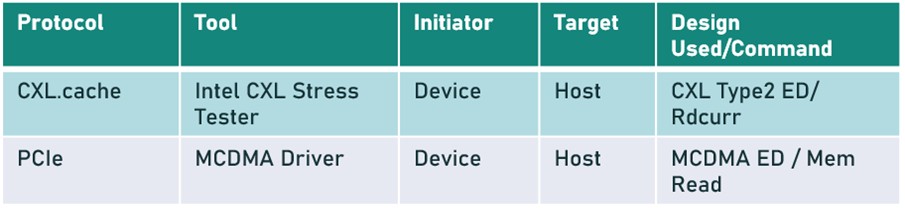
Publicly disclosed performance metrics have emerged, illustrating the latency advantage of CXL Type 2 near memory acceleration vs. traditional PCIe®. The table below shows the offloading of the Kernel Same-Page Merging (KSM) feature from the CPU to a CXL Type 2 device, resulting in an 83% lower tail latency, where the term tail latency refers to the 99th percentile of the latency distribution of a system.

The table below shows an example in which the measured CXL.cache latency is 68% lower than PCIe. The CXL.cache measurement assumes a hit in the CPU’s Last Level Cache (LLC), and the PCIe measurement assumes that read data is obtained from the host-attached DRAM.
As illustrated by the data points above, the CXL protocol allows for lower latency communication between the host and the accelerator device by introducing cacheable reads and writes between the host, device-attached memory, and accelerator. In addition to lower latency, CXL also simplifies communication by avoiding the kernel calls and DMA setups that are required by PCIe.

In summary, CXL-based memory tiering and near memory acceleration provide advantages such as reducing system TCO, offloading workload processing from the CPU, and decreasing processing latency for specific workloads.
Some challenges can be mitigated by FPGA-based solutions. Altera FPGAs provide CXL IP and design examples with configurable pre-built accelerator functions. The FPGA’s dynamic reconfigurability capability enables experimentation with workload partitioning and offloading from the CPU. Additional value-added features provided by Altera FPGAs include a Hard Processor System, and 100-800 GbE capability to expand CXL beyond the rack, with PCIe 5.0/6.0 connectivity.
To learn more, contact the Altera FPGA team at https://www.altera.com/contact.html.
References
(1) Meta, UMichigan – TPP: Transparent Page Placement for CXL-enabled Tiered-Memory: https://arxiv.org/abs/2206.02878
(2) Google – https://doi.org/10.1145/3582016.3582031
(3) SKHynix – https://www.youtube.com/watch?v=pbnTlY41h08
(4) SmartModular – https://www.youtube.com/watch?v=A_PML20fk-Y
(5) VMWare – https://www.youtube.com/watch?v=4tX8wJ-BJj8&list=PL0pU5hg9yniY-WFJ-uvAXKWVVaXXHLR7O&index=12
(6) Unifabrix – https://www.unifabrix.com/
Author
Divya Vijayaraghavan is a Technical Leader at Altera in San Jose. She has worn many hats in her career ranging from being a vertical champion and subject matter expert for UPI and CXL customer enablement and proliferation to a technical lead for FPGA acceleration solutions to a technical manager for several key customers and ecosystem partners. She has 26 granted patents and has represented Altera on industry standards committees such as the PCI-SIG.