By: Panmnesia
CXL 3.X technology is transitioning from discussion to real-world deployment, with growing industry attention on its necessity and potential. It is particularly well-suited as a standard for building large-scale, practical computing systems, as it enables more efficient resource utilization through memory sharing and enhances scalability and flexibility by supporting multi-level switching and fabric architecture founded on port-based routing (PBR).

To explore practical application domains for CXL 3.x technology, the team at CXL member company, Panmnesia, ran a variety of workloads on our CXL 3.x full-system framework**. As shown in the figure above, Panmnesia’s CXL 3.x full-system framework includes CXL-GPUs, CXL-Memory Expanders, and CXL-CPUs—each developed in-house using our CXL 3.x IP — the components of which are interconnected via our CXL 3.x Switch SoCs.
** This framework is an upgraded version of the CXL 2.0 full-system framework presented at the 2022 USENIX Annual Technical Conference [1].
As a result of our exploration, we determined that CXL 3.x technology is well-suited for the following two domains: AI infrastructure and high performance computing (HPC). In the following sections, we introduce why these are well-aligned with the characteristics of CXL technology, and how we accelerated representative applications for each domain using our CXL 3.x framework.
<Application Domain #1: AI Infrastructure>
Various AI applications, such as large language models (LLMs) and recommendation systems, have become deeply integrated into everyday life. As their impact continues to grow, companies are attempting to enhance AI model performance. The most common approaches include increasing the amount of training data to enable model learning from more diverse examples and increasing the number of model parameters to enable analyzation of more complex relationships. As these efforts continue, the sizes of models and datasets are growing rapidly. Consequently, many applications now require several terabytes or even tens of terabytes of memory [2, 3], easily exceeding the memory capacity of a single GPU (100-200GB in the latest GPUs [4]).
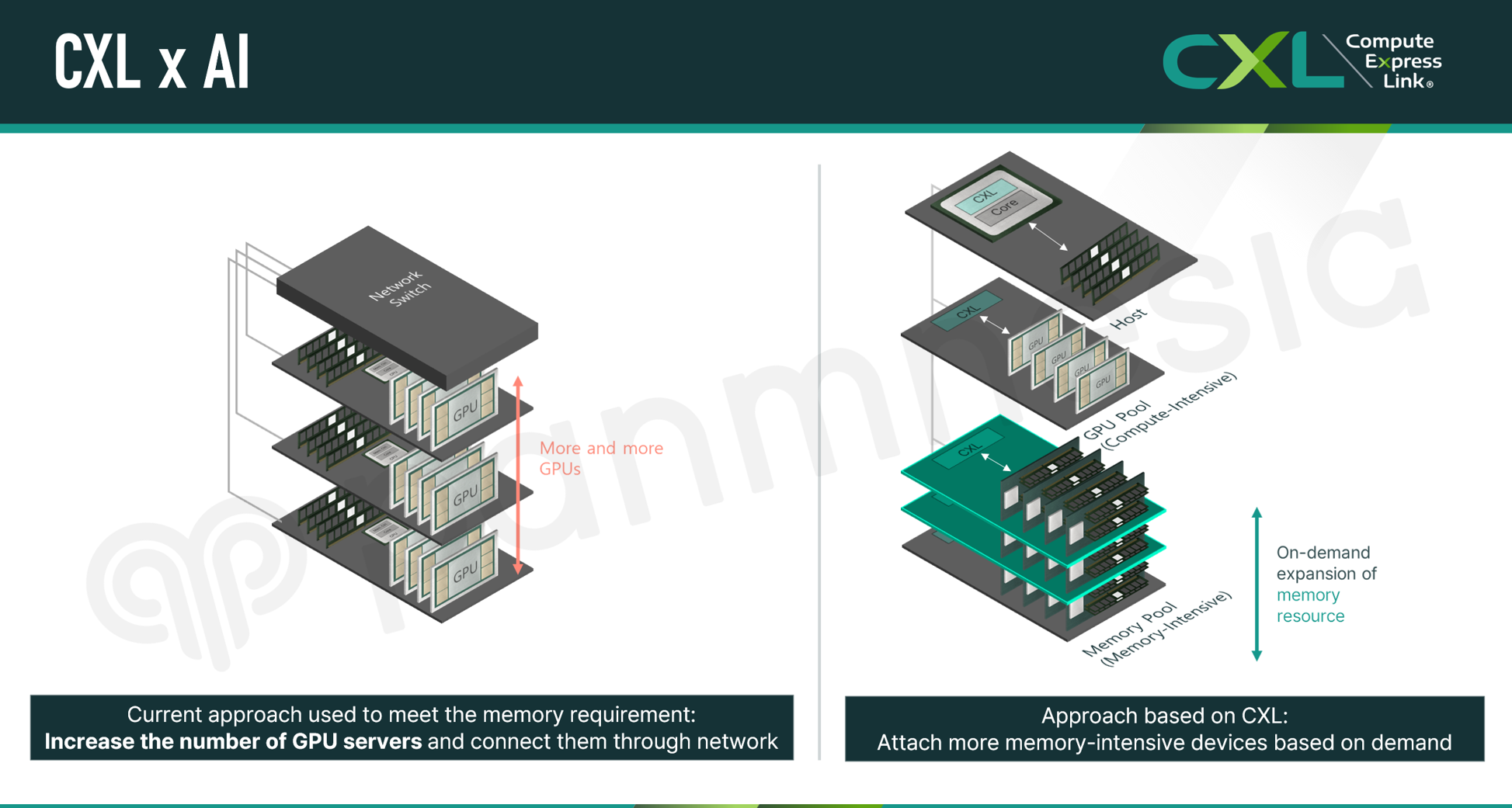
Traditionally, to compensate for insufficient memory capacity, more GPUs or GPU-equipped server nodes were allocated and interconnected via networks to run large-scale AI applications. However, considering that each AI application has different demands for compute and memory resources, the conventional approach of allocating resources with fixed compute-to-memory ratios often results in inefficient utilization and wasted resources. Given that individual data centers operated by major IT companies often house more than 10,000 GPUs, with total infrastructure costs reaching hundreds of millions of USD or more [5, 6], it has become essential to improve resource utilization.
To address this challenge, we have proposed several CXL-based solutions. As illustrated below, our approach places GPUs — or other AI accelerators — based on compute demand and resolves memory insufficiency by adding high-density memory devices (i.e., CXL-Memory Expanders) or memory nodes. This approach minimizes resource waste compared to the conventional method of adding more GPUs or GPU-equipped servers solely to secure sufficient memory capacity. In other words, build and operating costs are significantly reduced. In the following section, we present two representative CXL-based systems—built upon the aforementioned approach—to enhance resource efficiency in AI infrastructure.

The first system integrates a CXL root complex within the GPU/AI accelerator itself. By connecting CXL memory expanders or CXL-SSDs to this root complex, the GPU system’s memory capacity increases, and to the host (which accesses the GPU as an endpoint device), it simply appears as if the GPU’s memory has grown.
Note that Panmnesia’s CXL IP, embedded in the CXL controller of each device, handles operations such as cache coherence management in a hardware-automated manner. As a result, higher performance than previous approaches like unified virtual memory (UVM [7]), where the host software manages the GPU’s access to external memory spaces, is achievable.

In fact, when we built a prototype based on our CXL IP and evaluated its performance, we confirmed that it exceeds UVM performance by 3x. More details about this system can be found in Panmnesia’s recent blog: https://panmnesia.com/technology/blog/2024-06-25-cxl-gpu-techblog/.

The second system utilizes the GPU/AI accelerator as a Type 2 device. We unveiled this system — the CXL-Enabled AI Cluster — at last year’s OCP Global Summit. The framework consists of GPU nodes and memory nodes interconnected via Panmnesia’s CXL 3.x Switch. It allows users to allocate only as much compute (GPU/AI accelerator) and memory resources as required from each node (pool) based on resource demand, minimizing unnecessary resource waste.

To validate the practicality of this framework, we ran and evaluated the performance of a retrieval-augmented generation (RAG) application, which is commonly used in major AI chatbots today. In short, RAG enhances the accuracy of LLM inference by retrieving documents related to the user’s query from a vector database and using them as additional input to the LLM. Given that vector databases can be tens of terabytes in size, many previous studies have proposed storing them on storage devices like SSDs [8, 9]. In our approach, we stored the vector database in a large memory pool built with CXL technology, while running the LLM on a GPU pool.

Our tests showed that the CXL-based system eliminated the delays typically caused by slow storage access in SSD-based systems and minimized communication overhead as our CXL IP achieved more than six times the performance. Watch this video demo for more information: https://www.youtube.com/watch?v=lrhd4fu0KTc.
This is only a partial representation of our efforts. In addition to the work described above, we continue to demonstrate the practicality of CXL through a variety of real-world use cases powered by Panmnesia’s core products—CXL switch SoC and CXL IP. In our next blog, we will discuss CXL’s impact on HPC workloads. Further details can be found on our website: https://panmnesia.com.
References
[1] Donghyun Gouk, Sangwon Lee, Miryeong Kwon, and Myoungsoo Jung. Direct Access, High-Performance Memory Disaggregation with DirectCXL. 2022 USENIX Annual Technical Conference (USENIX ATC 22).
[2] Harsha Simhadri. Research talk: Approximate nearest neighbor search systems at scale. https://youtu.be/BnYNdSIKibQ?si=WoSWfJTVLEd2Rk62
[3] Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. Fast approximate nearest neighbor search with the navigating spreading-out graph. Proceedings of the VLDB Endowment, 2019.
[4] NVIDIA. NVIDIA H200 Tensor Core GPU. https://www.nvidia.com/en-us/data-center/h200/
[5] Business Insider. Elon Musk quietly built a 2nd mega-data center for xAI in Atlanta with $700 million worth of chips and cables. https://www.businessinsider.com/xai-elon-musk-x-new-atlanta-data-center-2025-2
[6] The Globe and Mail. OpenAI’ First Stargate Site at Texas to Host 400K Nvidia (NVDA) AI Chips. https://www.theglobeandmail.com/investing/markets/stocks/MSFT/pressreleases/31469159/openai-first-stargate-site-at-texas-to-host-400k-nvidia-nvda-ai-chips/
[7] NVIDIA. Unified Memory for CUDA Beginners. https://developer.nvidia.com/blog/unified-memory-cuda-beginners/
[8] Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. Diskann: Fast accurate billion-point nearest neighbor search on a single node. Advances in Neural Information Processing Systems (NeurIPS), 2019.
[9] Siddharth Gollapudi, Neel Karia, Varun Sivashankar, Ravishankar Krishnaswamy, Nikit Begwani, Swapnil Raz, Yiyong Lin, Yin Zhang, Neelam Mahapatro, Premkumar Srinivasan, et al. Filtered-diskann: Graph algorithms for approximate nearest neighbor search with filters. Proceedings of the ACM Web Conference 2023 (WWW 23), 2023