By: Panmnesia
In our previous blog, we outlined the benefits of CXL for AI applications. However, we believe that beyond AI infrastructure, CXL can also be effectively applied to another representative large-scale computing system: HPC.
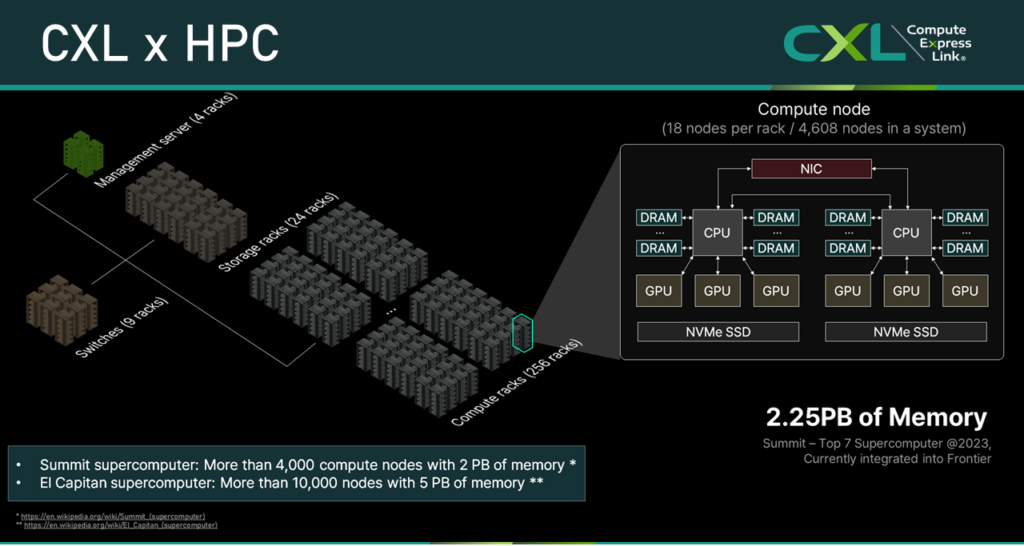
HPC primarily runs large-scale scientific simulations—from global-scale models to atomistic and molecular simulations—and is composed of many nodes interconnected via networks to handle the memory and compute demands of such large data processing applications. For example, the Summit supercomputer (now integrated into Frontier) consists of more than 4,000 compute nodes, storage nodes, and management servers [1], while the El Capitan supercomputer, currently the most powerful in the world, includes more than 10,000 nodes [2]. In such systems, users typically specify the number of nodes required for their job, and the resource scheduler assigns the appropriate nodes depending on availability and scheduling policies.
To run more simulations in such environments, it is important to allocate and efficiently employ only essential resources. However, as shown in the figure above, general HPC systems allocate resources in monolithic server units where compute and memory resources are mounted at fixed ratios, which limits resource utilization efficiency.
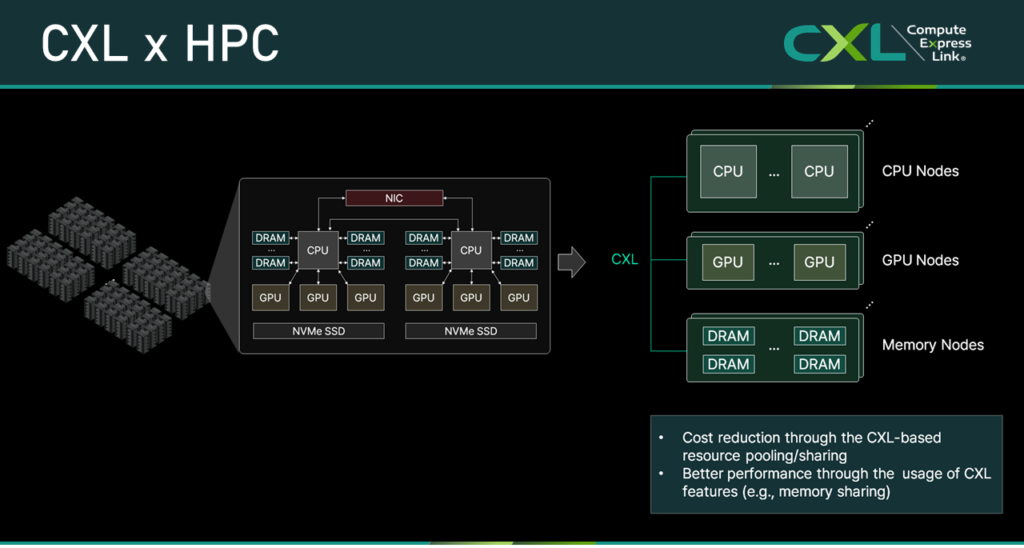
To address this, Panmnesia developed its CXL 3.x Composable Server, which we showcased at SC’24. This architecture consists of CPU, GPU, and memory nodes that can be allocated independently, allowing finer-grained resource provisioning — similar in concept to the CXL-Enabled AI Cluster (that we introduced in the previous blog post [3]). In addition, we proposed leveraging CXL 3.x’s memory sharing features to improve not just resource utilization but also performance.
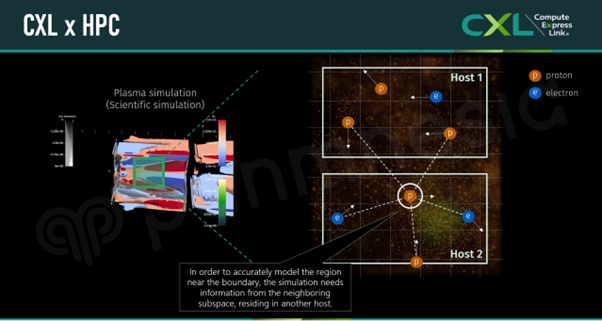
In this instance, our target for performance improvement was the ‘frequent network overhead that arises during parallel computing’. Typically, large-scale scientific applications like those described above simulate behaviors or states within a ‘simulation space.’ Since the memory and compute demands of these simulations exceed what a single processor can handle, the simulation space is divided into multiple ‘subspaces,’ each assigned to a separate host. Each host then predicts the state changes of components within its assigned subspace in parallel.
However, to accurately model components near the boundaries between subspaces, each host must consider interactions with components located in neighboring subspaces (managed by other hosts), which requires accessing data from those hosts. Such data exchanges typically rely on network-based communication, introducing redundant data copies and software interrupts as data passes through the network stack.
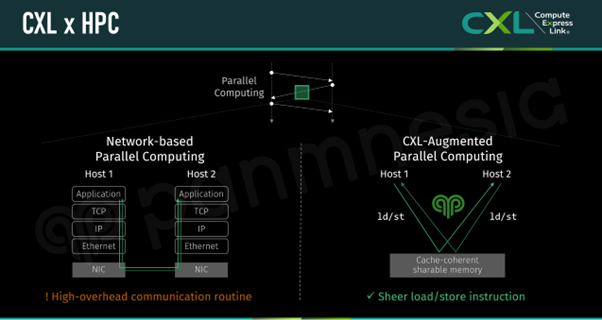
To mitigate performance degradation caused by network overhead, we enabled hosts to share data by writing to and reading from a shared CXL memory space (i.e., the memory node in the CXL 3.x Composable Server) rather than going through the network stack. In this configuration, the only action required by each host for data exchange is to issue load and store commands, as Panmnesia’s CXL 3.x IP automatically handles memory sharing and back-invalidate operations. This reduces software interruptions and eliminates redundant data copies by bypassing the network stack, thereby minimizing performance overhead.
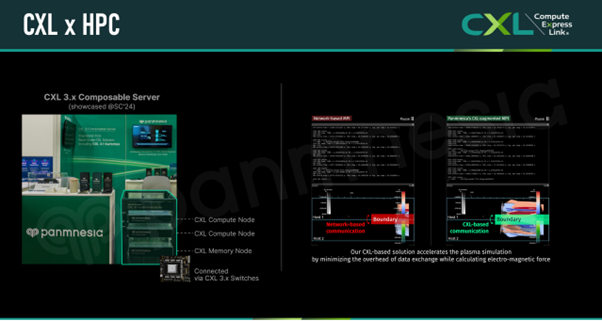
We evaluated this solution by running a plasma simulation – a representative parallel computing workload—and compared its performance against that of a conventional network-based system. As a result, our CXL-based system achieved about 1.8 times better performance. We also showcased a simplified version of this Composable Server at CXL DevCon 2025, and a demo is available at the following link: https://youtu.be/N3-pFVFA6RI.
Panmnesia will continue to demonstrate the benefits of CXL through a variety of real-world use cases powered by Panmnesia’s core products—CXL switch SoC and CXL IP. As part of this effort, Panmnesia will showcase our CXL 3.X Switch-Based Memory Pooling and Sharing in a Multi-Host Environment at the CXL Pavilion (Booth no. 817) during Supercomputing 2025. Visit the Pavilion to meet with our representatives and to see CXL in action!
Learn more about Panmnesia by visiting our website: https://panmnesia.com.
References
[1] Wikipedia. Summit (supercomputer). https://en.wikipedia.org/wiki/Summit_(supercomputer)
[2] Wikipedia. El Capitan (supercomputer). https://en.wikipedia.org/wiki/El_Capitan_(supercomputer)
[3] CXL Consortium Blog. Exploring CXL Use Cases with CXL 3.X Switches for AI Applications. https://computeexpresslink.org/blog/exploring-cxl-use-cases-with-cxl-3-x-switches-for-ai-applications-4166/