I recently moderated the “Exploring Coherent Memory and Innovative Use Cases” webinar, during which we explored many topics.
These included:
- How CXL technology maintains coherency between the CPU memory space and attached device memory
- The methods by which CXL views memory components namely processors, cashing agents and systems
- The many uses cases of CXL
- We received great questions during the webinar but ran out of time to answer them all. We have provided answers to these questions below.
If you were unable to attend the live webinar, the full recording is available on BrightTalk and YouTube. Also, the presentation is downloadable from the resource library section of the CXL website. If would like information on future webinars, please register on the CXL Consortium BrightTalk channel.
CXL Cache Coherency
Q: Can a device use the CXL.cache interface without having any memory (or very little memory) on the device so it has access to the host cache?
Yes, this is a type 1 device. A type 1 device enables devices that use CXL.cache protocol on top of CXL.io.
Q: Is there a cache semantic for a Block Rd Modify Write atomic operation?
All accesses on CXL.cache are 64-byte granular. Atomicity is not guaranteed after 64 bytes.
Q: If there are multiple devices, can a device directly access and cache data in the memory of another device (not of the Host)?
Yes, assuming the requesting device targets memory in peer CXL devices, the peer device is a type 2 or type 3 (i.e., device has .mem protocol), and the requesting device is a type 1 or type 2 (has .cache protocol). The coherency is still performed by the home agent that is in the CPU. The memory need not be part of CPU.
Q: Can you show examples where a cacheline in “I” state in all peer caches, and the data reference is fetched from memory?

Q: Any option to enable/disable IO, memory or cache CXL?
CXL.io is mandatory, and we expect devices to have either CXL.mem and/or CXL.cache. (link to CXL 1.1 overview)
Q: Why is data not sent by the peer cache? Why does it have to come from memory controller?
In the CXL.cache protocol, data is given to the device from the Home Agent only. That data can come either from peer cache or memory controller. The device doesn’t need to know who sent the data.
Q: What happens when there are too many coherent requests from CXL devices to one Home Agent? Does Home agent become a bottleneck?
There can be bandwidth bottlenecks in the system if you have many caches going through one memory controller or one home agent. CXL handles this by back pressuring the CXL host-to-device (H2D) request channel.
Q: So which home agent in this picture is responsible for resolving coherency?
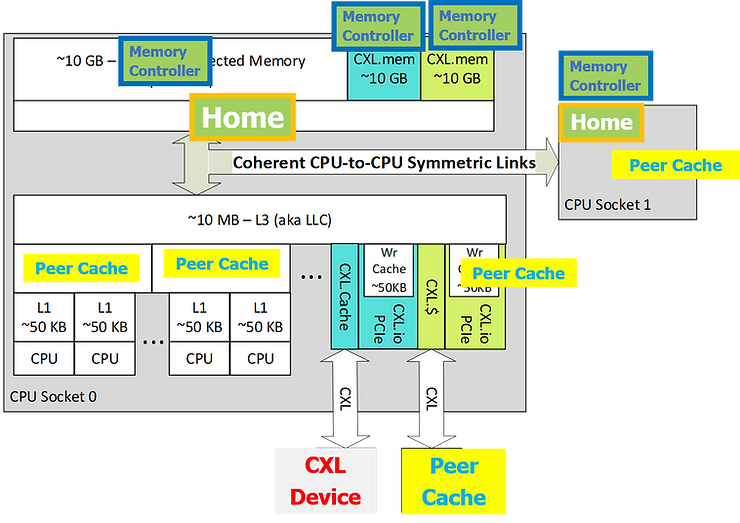
- For every cache line address, there is only one home agent responsible for that address/memory region.
- Home Agents exist in CPUs.
- Each home agent is responsible for one or more memory devices and/or memory regions.
- The Home Agent works with the caching agent in the CPU to resolve the coherence conflicts.
Data Sharing between CPU and Accelerator or Accelerator and Accelerator
Q: In the context of the fact that CXL is targeting fine-grained data sharing, I want to know the potential advantage of CXL when using CXL type 2 devices, which is an accelerator. But, are there any workloads that can exploit that fine-grained sharing? Also, AI accelerators operate in Producer-consumer ordering, which is done well in PCIe DMA currently. Are there any workloads that require “a lot of” fine-grained data sharing?
PCIe is optimized for DMA and block data transfers, so producer/consumer ordering is the suitable mechanism for data consistency. A fine-grained synchronization using cachelines or cacheline-based is more efficient and does not require doorbells or interrupts which normally increase overhead of synchronization tasks and thereby latency.

Q: Should the GO-E and Data be an atomic operation? Why can’t they come separately?
GO-E messages are small messages which have an ordering requirement with other small messages. The larger Data payload message would be costly to implement as an ordered message. By sending them separately we avoid the need for ordering on the Data payload.
Q: Why can’t a CXL device send Data along with Dirty Eviction phase during writes, as it has exclusive access in that phase?
This is done to simplify the Home Agent, where the Home Agent will only accept the data after it has allocated resources to sink it.
Q: Is Evict analogous to a “flush” in more common cache terminology?
Not completely. The “flush” is an explicit command which moves data out of the cache into memory. Whereas, eviction is a consequence of a cache line being replaced.
Q: Can you share an example of a use case for an Exclusive access please?
On the first read allocation, exclusive access is given to allow the reader to later modify the cache line without writing data or sending snoop probes on the CXL Link (silent write).
Q: What do you mean by disaggregation? How does CXL solve this problem?
CXL technology offers a high-bandwidth, low-latency interconnect that makes compute dis-aggregation possible by placing memory, storage, networking devices farther away from the CPU. Placing accelerator and accelerator devices away from the CPU using parallel BUS-es has been difficult in the past. CXL facilitates the disaggregation using SERDES techniques for these connections. For more information, view our webinar presentation deck here.
Read and Write Operations
Q: What will be the total round-trip latency of read and write operations, when using CXL device and starting from invalidate state?
This is not specified by CXL Consortium or our specification. It really depends on the device implementation attribute. We have guidelines, but it hinges on the media and the interconnect length, DRAM or storage-class memory latency. The CXL specification itself has 50 nanoseconds of additional latency as a guideline.
Latency
Q: What latency needs to be supported to provide cache coherency without system impact? Has it been quantified?
The CXL specification does give guidance on clean snoop response latency.
Q: How does CXL achieve low latency? Is it by introducing the device biases and multiplexing three different sub protocols?
In contrast with PCIe protocol, for short packet/payload and load/store semantics, the CXL specification has introduced dedicated pathways and relaxed ordering rules for CXL.cache and CXL.mem protocols in a CXL device or in a CPU. Dedicated here in contrast with the CXL.io traffic which is optimized for block data transfers via DMA.
Implementation
Q: Do we need to have a new CPU to support CXL technology?
CXL technology is an evolution based on the PCIe physical layer. As CPUs start to implement CXL technology, features provided by CXL devices will become readily available.
Q: Can’t we use our own coherency protocol inside the chip? We would like to add CXL to our existing coherency system.
CXL technology is a protocol exposed to the device. CXL specification is silent on a specific device implementation.
Miscellaneous
Q: How does the communication happen between transmitter CXL link layer and receiver CXL link layer?
The link layer has control flits to allow link layer to link layer communication for initialization and retry recovery.
About CXL
Q: If I want to add CXL to our system, who do I need to reach out to?
The CXL Consortium offers two membership levels, Contributor or Adopter.
As a Contributor, you can participate in all CXL Consortium working groups (technology and marketing), influence the direction of the technology, access the intermediate specification and more. Learn more about the benefits of becoming a CXL Consortium member here. Currently we have the following working groups which operate under CXL Technical Task Force (TTF): Compliance, Memory System, PHY, Protocol, and Software & Systems. The Marketing Working Group and the TTF report to CXL Board of Directors (BoD).
As an Adopter, you can have access to the final specification releases and gain the IP protection as outlined in the IPR Policy for RAND terms.
Both Contributor and Adopter level member applicants must review and agree to the incorporation documents – including the Corporate Bylaws, the Intellectual Property Policy, and the Antitrust Policy prior to signing the membership agreement.
Interested in becoming a member of the CXL Consortium and getting involved with one of our working groups? Please contact admin@computeexpresslink.org with any inquiries.
Q: I would like to follow CXL via social media. How do I get connected?